Power Plants Data¶
In this exercise, we will use the powerplants.csv dataset from the powerplantmatching project. This dataset contains information about various power plants, including their names, countries, fuel types, capacities, and more.
URL: https://raw.githubusercontent.com/PyPSA/powerplantmatching/master/powerplants.csv
Task 1: Load the dataset into a pandas DataFrame.
Notebook Cell
import pandas as pd
url = (
"https://raw.githubusercontent.com/PyPSA/powerplantmatching/master/powerplants.csv"
)
df = pd.read_csv(url, index_col=0)Task 2: Run the function .describe() on the DataFrame.
Notebook Cell
df.describe()Task 3: Provide a list of unique fuel types and technologies included in the dataset.
Notebook Cell
df.Fueltype.unique()array(['Hydro', 'Hard Coal', 'Natural Gas', 'Lignite', 'Oil', 'Wind',
'Solid Biomass', 'Waste', 'Solar', 'Geothermal', 'Battery',
'Heat Storage', 'Nuclear', 'Other', 'Biogas', 'Mechanical Storage',
'Hydrogen Storage'], dtype=object)Notebook Cell
df.Technology.unique()array(['Pumped Storage', 'Reservoir', 'Run-Of-River', 'Steam Turbine',
'CCGT', 'Onshore', 'OCGT', nan, 'PV', 'Offshore', 'Li', 'Csp',
'Pb', 'NaS', 'NiCd', 'CSP', 'CAES', 'Molten Salt', 'V', 'NaNiCl',
'Combustion Engine'], dtype=object)Task 4: Filter the dataset by power plants with the fuel type “Hard Coal”.
Notebook Cell
coal = df.loc[df.Fueltype == "Hard Coal"]
coalTask 5: Identify the 5 largest coal power plants. In which countries are they located? When were they built?
Notebook Cell
selection = coal.Capacity.nlargest(5).index
selectionIndex([562, 588, 2514, 195, 2536], dtype='int64', name='id')Notebook Cell
coal.loc[selection, ["Name", "Country", "Capacity", "DateIn"]]Task 6: Identify the power plant with the longest name.
Notebook Cell
i = df.Name.apply(lambda x: len(x)).argmax()
df.iloc[i]Name Sonnenkraftwerk Albert Pielhau Gmbh Co Kg Gese...
Fueltype Solar
Technology NaN
Set PP
Country Germany
Capacity 0.168
Efficiency NaN
DateIn 2014.0
DateRetrofit NaN
DateOut NaN
lat 51.16537
lon 7.482275
Duration NaN
Volume_Mm3 NaN
DamHeight_m NaN
StorageCapacity_MWh NaN
EIC {nan}
projectID {'MASTR': {'MASTR-SEE920161926752'}}
Name: 132719, dtype: objectTask 7: Identify the 10 northernmost powerplants. What type of power plants are they?
Notebook Cell
index = df.lat.nlargest(10).index
df.loc[index]Task 8: What is the average start year of each fuel type? Sort the fuel types by their average start year in ascending order and round to the nearest integer.
Notebook Cell
df.groupby("Fueltype").DateIn.mean().round().sort_values()Fueltype
Hard Coal 1972.0
Hydro 1973.0
Lignite 1978.0
Nuclear 1981.0
Other 2000.0
Geothermal 2003.0
Oil 2004.0
Waste 2004.0
Solid Biomass 2007.0
Wind 2011.0
Biogas 2012.0
Natural Gas 2012.0
Solar 2017.0
Battery 2023.0
Heat Storage NaN
Hydrogen Storage NaN
Mechanical Storage NaN
Name: DateIn, dtype: float64Wind and Solar Capacity Factors¶
In this exercise, we will work with a time series dataset containing hourly wind and solar capacity factors for Ireland, taken from model.energy.
Task 1: Use pd.read_csv to load the dataset from the following URL into a pandas DataFrame. Ensure that the time stamps are treated as pd.DatetimeIndex.
Notebook Cell
url = "https://model.energy/data/time-series-2b42655fa0b49b73fb15871dba2f7000.csv"
df = pd.read_csv(url, index_col=0, parse_dates=True)Task 2: Calculate the mean capacity factor for wind and solar over the entire time period.
Notebook Cell
df.mean()onwind 0.366898
solar 0.099274
dtype: float64Task 3: Calculate the correlation between wind and solar capacity factors.
Notebook Cell
df.corr()Task 4: Plot the wind and solar capacity factors for the month of May.
Notebook Cell
df.loc["05-2011"].plot(ylabel="capacity factor")<Axes: ylabel='capacity factor'>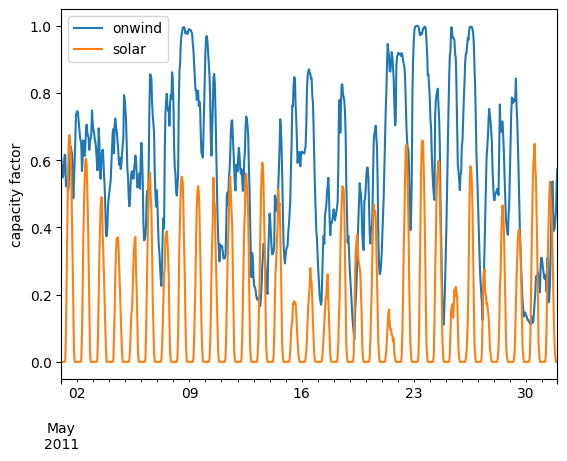
Task 5: Plot the weekly average capacity factors for wind and solar over the entire time period.
Notebook Cell
df.resample("W").mean().plot()<Axes: >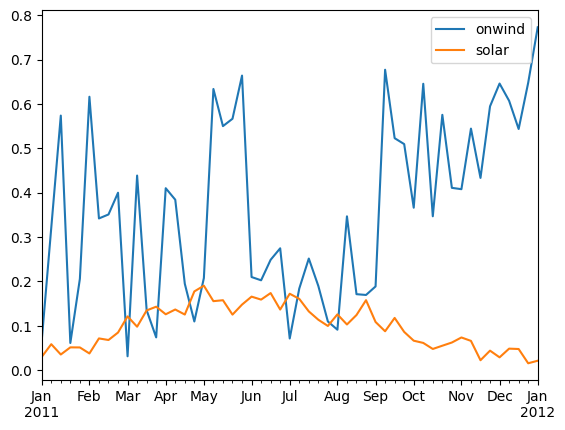
Task 6: Go to model.energy and retrieve the time series for another region of your choice. Recreate the analysis above and compare the results.